专业形象:能用 AI 做的页面就用 AI 做, 对标国外上市公司
方便管理:产品多、博客多,WP外贸通用版适合任何行业
转化率高:有利于SEO+谷歌广告+社媒的询盘订单转化率
AI 制作 High-end 页面(形象) WordPress 管理海量产品(功能) 谷歌 SEO 架构优化(流量)
基于草根外贸开发版 (sourcify.fobwp.com) 架构,支持 AI 页面上传
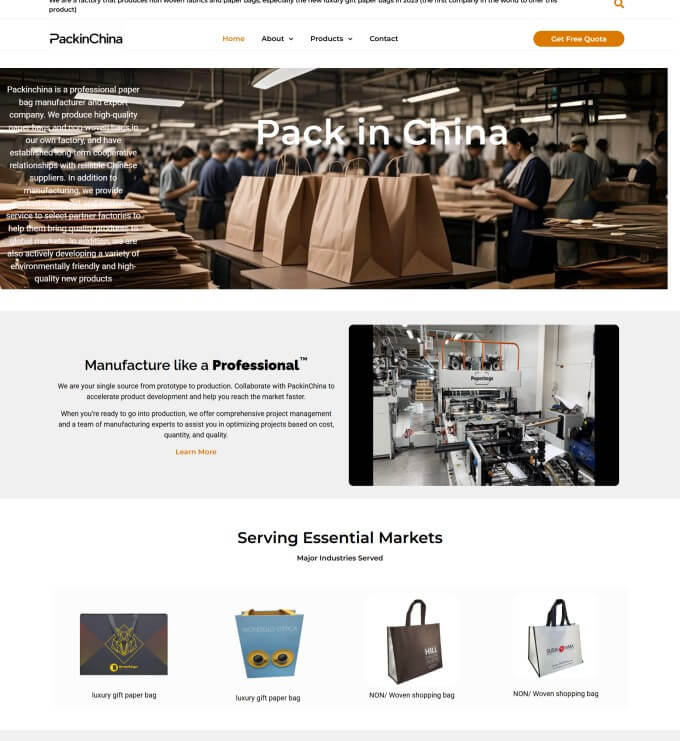
适合产品少(< 50款)、追求极致打开速度的起步 SOHO。
AI 负责形象,WP 负责管理。 适合产品多、看重数据私有的企业。
🏆 续费同享 ¥3,680/年 (包含VPS)
适合没有技术团队、追求高品质交付的老板。含人工策划、设计与上传。
1. 服务器包含: 上述2980元以上的所有建站套餐方案均已包含稳定快速的国外独立IP服务器/VPS费用 (首年),无需额外购买。
2. 单独购买: 如果您已有网站只需服务器,参考 Hosting 服务。
3. 源码自主权: 我们提供完全独立的源代码。如果您希望将网站部署在您自己的服务器上,需支付 ¥3,000 源代码开发部署技术服务费。
查看代理/自托管方案4. 维护说明: 使用我们的服务器享受免费技术维护。如果客户使用自己的服务器,独立站出现问题需我们协助修复,费用 ¥1,000 起/次。
主要线上交流,省去无效沟通,最快3天交付
看案例,定方案。微信支付,提供域名信息。
我们技术团队在 3 天内为您开通独立后台。
您按照视频教程上传产品(或由AI系统自动生成文章)。
提交谷歌收录,开始SEO或广告推广,等待询盘。
环环相扣,缺一不可
建立正确的 SOP 思维,规划未来 1-3 年的增长路径。
从 1680 DIY 到 19800 混合架构,匹配不同阶段的企业。
AI 内容铺词 + 供应链外链背书 = 谷歌排名飙升。
AI 定制页提高转化率,EDM 和 CRM 锁住每一个商机。
创始人 William 亲自带队,不讲理论,只讲实操。
1对1 腾讯会议屏幕共享教学,手把手教您如何通过 AI 编程修改网站、优化 SEO、投放广告。
| 网站域名 | 行业 | 策略 | 真实效果 |
|---|---|---|---|
| hy-proto.com | 机械加工 | AI铺词 | 流量涨 4900% |
| cospaks.com | 化妆品包装 | 6800套餐 | 询盘翻 3 倍 |
| sourcifychina.com | 采购平台 | AI内容 | 询盘1年3000个 |
在这个浮躁的行业,我们坚持长期主义
创始人 William 开始 SOHO 外贸生涯,积累第一手实战经验。
成为 **福步论坛(FOB)** 第一家战略合作建站服务商。
全面引入 WordPress + VPS 体系,与国际技术接轨。
推出 **AI 建站与流量增长系统**,帮助客户低成本获取谷歌询盘。